

Google just released Gemma 4 12B, and it sits in a pretty interesting position within the Gemma family. It’s not the smallest model they offer, and it’s not the biggest. It’s the one that actually fits on your laptop.
Specifically, it runs on hardware with 16GB of VRAM or unified memory. That puts it in range of a lot of consumer-grade machines, including Apple Silicon laptops, without needing to rent a cloud GPU to get serious work done. For developers who want to run real multimodal inference locally, that matters quite a bit.
What Makes It Different: No Encoders
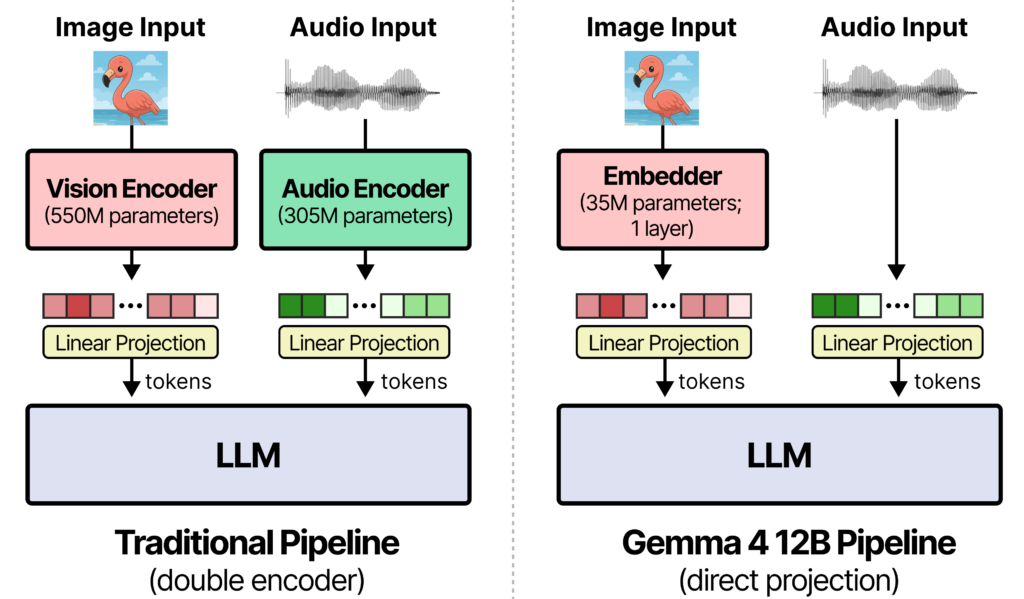
The most technically interesting thing about Gemma 4 12B is the architectural choice at its core. Most multimodal models rely on separate, dedicated encoders to process images and audio before the language model ever sees them. The vision encoder handles images, the audio encoder handles sound, and then those outputs get handed off to the LLM. It works, but those separate components add latency and fragment the model’s memory footprint.
Gemma 4 12B skips that entirely. Vision and audio inputs go straight into the LLM backbone. There’s no separate encoder sitting in between.
For vision, Google replaced what had been a 550M parameter vision transformer in their other mid-sized models with a much lighter 35M parameter embedding module. Raw 48×48 pixel patches get projected to the LLM’s hidden dimension through a single matrix multiplication, with positional information attached using a factorized coordinate lookup. The language model itself then handles visual processing from there.
Audio is treated even more directly. Instead of routing sound through a dedicated encoder with conformer layers, raw 16 kHz audio signals are sliced into 40ms frames and projected linearly into the same input space as text tokens. The model sees audio the same way it sees words.
The practical upside beyond speed is that fine-tuning gets simpler. Because text, images, and audio all share the same weights, you don’t need to coordinate separate frozen encoder components during training. A LoRA adapter or a full fine-tune naturally updates the entire multimodal pipeline in one pass. Learn more here.
Where It Sits in the Gemma 4 Lineup
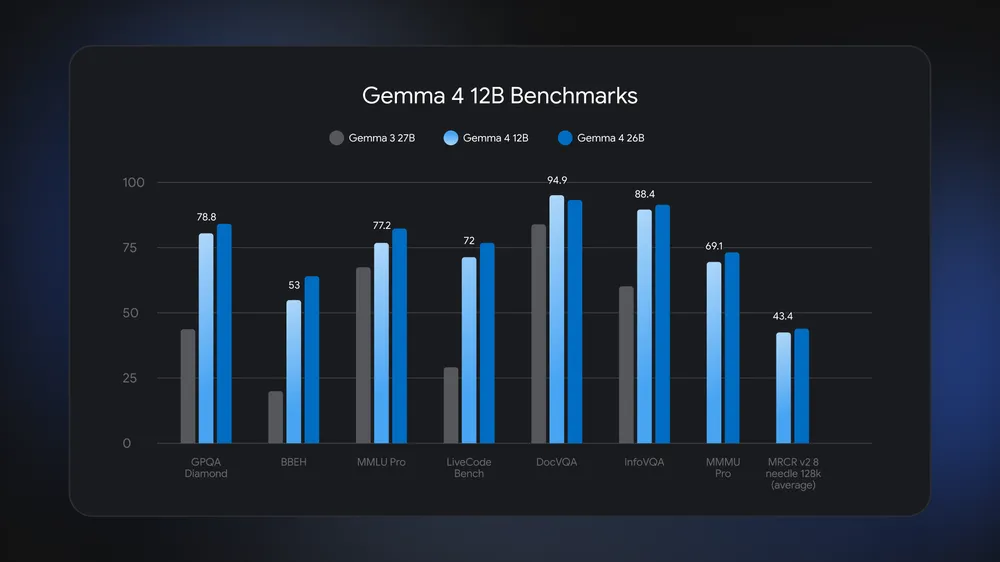
The Gemma 4 family now spans a few different sizes and use cases. On the lightweight end is the E4B, designed for edge and mobile deployment. On the more powerful end is the 26B Mixture of Experts model. Gemma 4 12B is a dense model that lands between them, and according to Google, it benchmarks close to the 26B MoE on standard evaluations despite having less than half the memory footprint.
There’s also a notable first for this model within the Gemma line: it’s the first medium-sized Gemma model to support native audio input. Audio capability existed before in smaller edge models like the E2B and E4B, but this is the first time it’s available at this scale.
Agentic and Multimodal Capabilities
Beyond basic image and audio understanding, Gemma 4 12B is positioned as a model for building local agents. Google’s developer guide shows it being used with agent harnesses like OpenCode to write and execute code, process images through tools it builds itself, and analyze multi-minute video segments with combined frame and audio input.
One example from the guide involves processing five minutes of video at one frame per second alongside the original audio, with the model correctly reasoning about what’s happening visually and aurally at the same time. That kind of combined video and audio understanding at this model size, running locally, isn’t something that’s been widely accessible before.
The model also comes paired with a Multi-Token Prediction drafter, which is designed to reduce inference latency by generating multiple tokens in parallel rather than strictly one at a time. For agentic tasks that require back-and-forth reasoning, that kind of speed improvement adds up.
On-Device Tools and Desktop App
The release includes some new on-device developer tooling that’s worth paying attention to. Google AI Edge Gallery, which was previously a mobile app, is now available as a macOS desktop application. It runs Gemma 4 12B fully offline on Apple Silicon, and it includes a sandboxed Python execution environment so the model can write, run, and plot code directly within the chat interface.
There’s also a new CLI command for spinning up a local, OpenAI-compatible API server using LiteRT-LM:
shell
litert-lm import --from-huggingface-repo=litert-community/gemma-4-12B-it-litert-lm gemma-4-12B-it.litertlm gemma4-12b
litert-lm serveOnce running, it connects to standard developer tools like Continue, Aider, or OpenCode. It uses stateless prefix caching to handle context history and skip redundant prefill computation, which helps keep local inference responsive.
Licensing and Availability
Gemma 4 12B is released under an Apache 2.0 license. Weights for both the pre-trained and instruction-tuned versions are available on Hugging Face and Kaggle. It works with Hugging Face Transformers, llama.cpp, MLX, SGLang, vLLM, and Unsloth for fine-tuning. Cloud deployment options are available through Google Cloud’s Model Garden, Cloud Run, and GKE for teams that want to serve it at scale rather than locally.
The Gemma family has now passed 150 million downloads across its models. Gemma 4 12B is the newest addition to that ecosystem, and it’s clearly aimed at developers who want capable, locally-runnable multimodal inference without needing specialized hardware to get there.





